
Open Source Twisted Sequential Monte Carlo
Can Twisted SMCs scale search for LLMs? Maybe.


How do you scale language model search? Can a language model be guided towards solving new problems that it usually cannot solve purely through guided resampling without training the model whatsoever? Turns out the answer is sorta yes. This has important implications for post-training and safety research.
First, it might be tempting to use MCTS. After all it worked for AlphaGo so well. On that topic I don't believe it's an accident that AlphaGo & AlphaZero are arguably the only examples of ASI that we have so far. But MCTS works well for domains with small discrete action spaces and zero sum games. But language models are different.
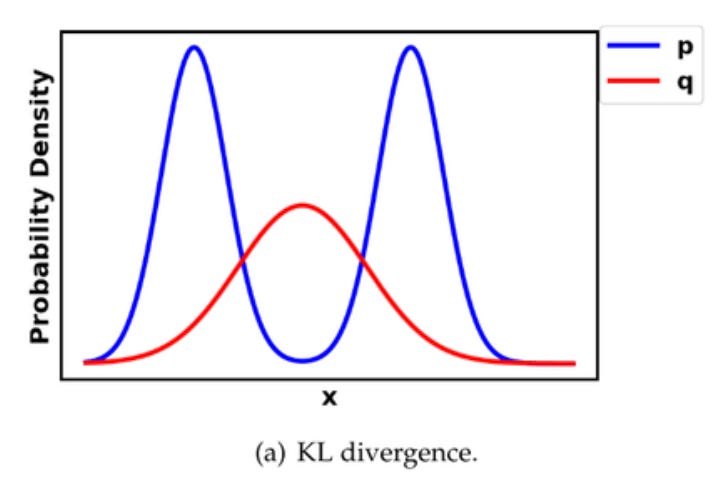
In transformer based models we sequentially generate tokens based on training to mimic internet data. But anyone who has played with base models has seen we lose a tremendous amount of diversity in post training. This is widely believed to be due to mode collapse.
Well if not MCTS what else? Thanks to a technique called Twisted Sequential Monte Carlo, we can actually learn twist functions that learn to score and resample promising completions that might not have reward early on or might be the first reward getting completions we get early on.

One way to think about this is that we can always score a partial sequence by taking the probability weighted average of ALL possible future completions, but this is combinatorially impractical.
Twisted SMC learns to sample by scoring partial sequences with a twist function that computes sampling weights via a telescopic product of partition functions ending in a final one that could be computed by your reward function.
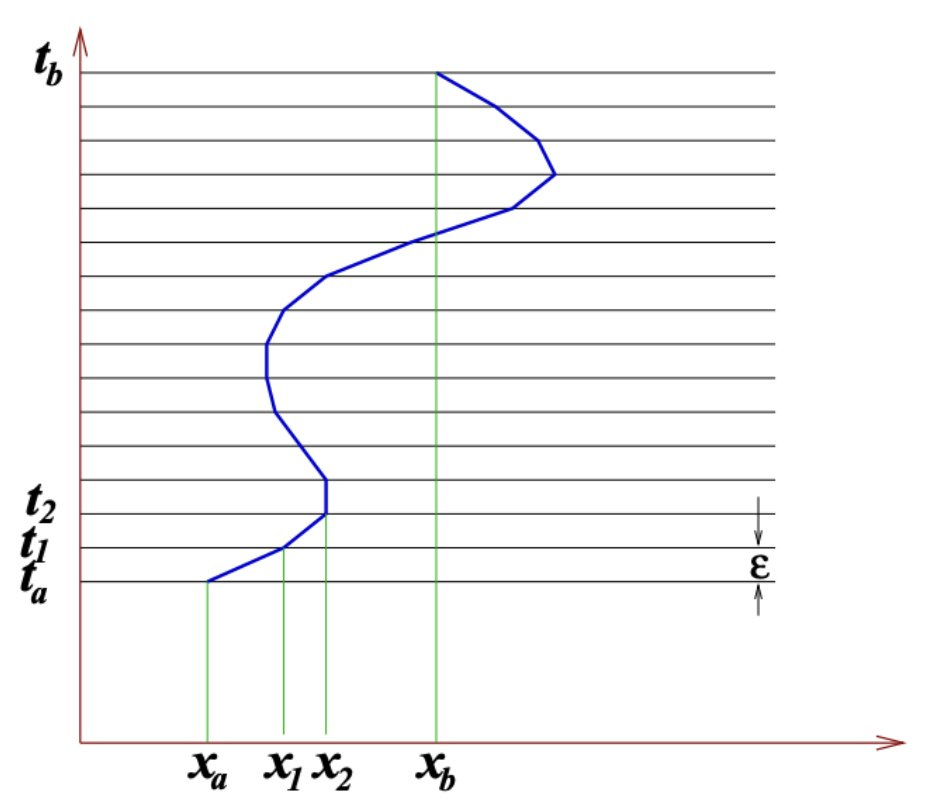
As an aside this has interesting connections with the path integral from physics where we sum over all spacetime trajectories weighted by a potential. Physicists use similar technique to do calculations where the path integral has no analytical solution like in quantum chromodynamics (QCD) which generally has no perturbative solutions.
In any case I was able to get Qwen1.5 B to sample more reward yielding sequences for GSM8K problems more effectively without training it. These were rewards developed in a now famous gist for GRPO.
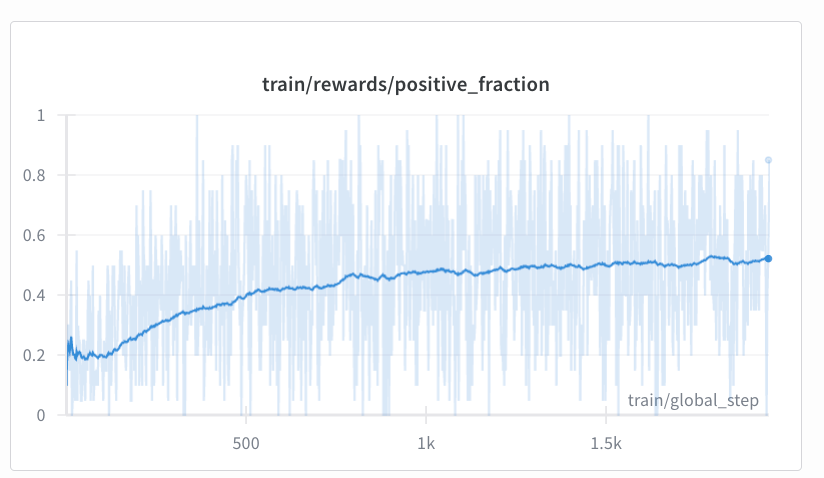
What’s the catch ? It's very computationally intense but I like to think this makes this "bitter-lesson-pilled". In order to use this to train a base model you'd have to alternate between training the twist and then using the twisted SMC samples to train the model, which I was surprised just now to see a paper that does this (linked below).
Regarding the implications for safety research, more work would need to be done but twisted SMC shows we can potentially generate completions that are disfavored by the base model including potentially ones post trained out of the model so long as the model is capable of generating those completions at all.
I've implemented it as a HuggingFace Trainer although this probably wont work as is for other datasets besides GSM8K. I have not used their contrastive loss and have used an approximation for the twist proposal based sampling.
https://arxiv.org/abs/hep-lat/0702020 Discrete Feynman path integral image is from Colin Morningstar's review paper, who I worked with on this stuff as an undergrad years ago!
Special thanks to John Schulman for the fun convo that led to some weekend & evening hackery and research on my part.